Exploring Reinforcement Learning
This was initially a project done as part of Principles of Autonomy and Decision Making at Technische Hochschule Ingolstadt. The goal was to implement and test Q-Learning and Deep-Q-Learning in a custom environment.
Currently, this page serves as a gateway to exploring different RL algorithms on various environments, starting with Value function based methods.
1/ Q-Learning and Deep Q-Learning
1.1/ The Environment:
The custom environment was built on top of frameworks such as Gymnasium and PyGames. It essentially, involved an agent (Pikachu) who had to navigate it’s way through a maze toward’s the goal state (Ash) while collecting reward’s (badges) and avoiding terminal state’s (Meowth).
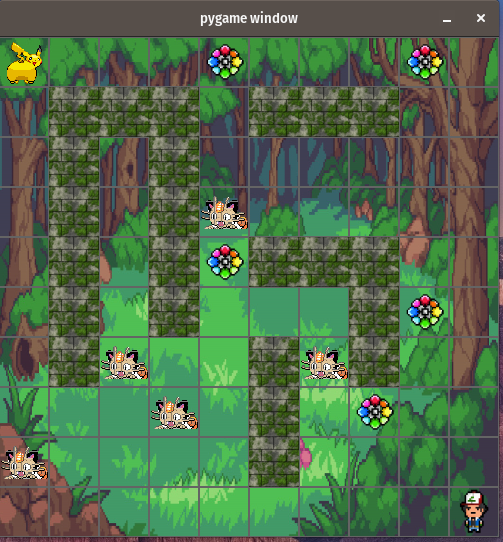
The following were few of the properties of the environment:
grid_size: 10x10
discrete_action_space: Up (0), Down(1), Left(3), Right(3) (Discrete(4))
hell_states: list of row, col position of terminal state's to avoid
observation_space: row,col position of the agent
badge_states: list of row, col positions of the badges in environment
rewards:
* Reach goal: +50
* Reach badge_state: +2
* Reach hell_state: -5
Note: We additionally force a time-limit to the agent, where
each step costs -0.05 in reward.
Episode end:
Episode end's if the following happens:
* Agent moves to the hell_state
* Agent reaches the goal at (10x10)
1.2/ Q-Learning:
We train a simple Q-Learning table of size N x M x C where,
N: No. of rows in environment
M: No. of columns in environment
C: Action Space within the envirionment
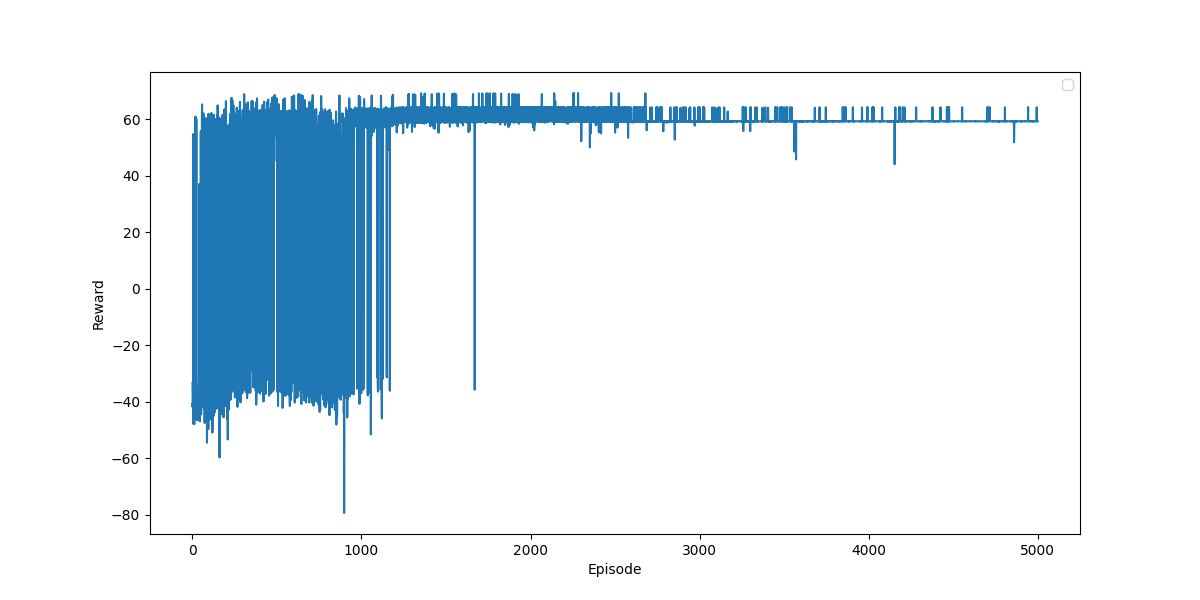
The hyperparameters for the policy chose are detailed below, the following picture shows, the learned path agent takes to move through the environment.

Hyperparmeters used to train the agent on the environment:
learning_rate: 0.01
gamma: 0.9
max_epsilon: 1.0
min_epsilon: 0.1
epsilon_decay: 0.995
Number of Episodes: 50_000
1.3/ Deep Q-Learning:
We train a simple Deep Q-Learning Network with three fully connected layers, the architecture is as follows:
The network takes in the current state of the agent, and outputs the estimated Q-values for all the actions.
# no_states = 2 (State St of agent)
# no_action = 4 (Action space)
nn.Linear(no_states, 16)
nn.Linear(16, 16)
nn.Linear(16, no_actions)
Hyperparameters for the same:
learning_rate = 0.001
gamma = 0.9
buffer_limit = 50_000
batch_size = 16
num_episodes = 10_000
max_steps = 1_000
MIN_EPSILON = 0.01
DECAY_RATE = 0.9999
MAX_EPSILON = 1.0